Iterative Dialectic Engine for Automated Learning
scientific method. The procedure by which, as a matter of definition, scientific laws, as contrasted with other kinds of general statement, are established. The orthodox view is that this procedure is inductive, but several philosophers of science have criticized inductivism as misrepresenting the actual procedure of scientists. Two phases of scientific activity need to be distinguished: the initial formulation of hypotheses, which seems mainly, as the anti-inductivists maintain, to be a business of inspired guessing that cannot be mechanised, and the confirmation of hypotheses thus formulated, which does appear to be a comparatively pedestrian and rule-governed undertaking. (1)
Induction and Popper's alternative view of scientific method have already been discussed, and discarded, in favour of iteration and dialectic respectively; and these latter processes have been invoked precisely in order to mechanise the "business of inspired guessing". So that's scientific method sorted - or is it? The opinion of Howson and Urbach, in their championing of Bayesian inference, is that
...scientific reasoning is reasoning in accordance with the calculus of probabilities. (2)
Without a doubt, for any closed, well-defined decision problem, probability theory can be used to indicate the optimal or 'rational' course of action. The difficulty is that very few problems in science or anywhere else are as well-behaved as the practical use of probability requires. Probability would be unnecessary without the presence of uncertainty, which comes in at least four variants:
Reliability/Failure of physical components, expressed as objective probability;
Safety/Risk of a system or activity, expressed as probability x cost;
Knowledge/Ignorance of certain facts, expressed as subjective probability;
Conviction/Doubt of certain statements, expressed as subjective degree of belief.
Each of these types of uncertainty can be quantified using probability; that's not the problem. The problem is that most practical decision problems involve more than one type of uncertainty, and the corresponding implementations of the probability calculus are incommensurate with one another, i.e. they cannot be combined in any meaningful fashion. Even if someone were able to invent a universal probability machine, a 'black box' capable of handling all types of uncertainty in an optimal fashion, would anyone trust it? Probably not.
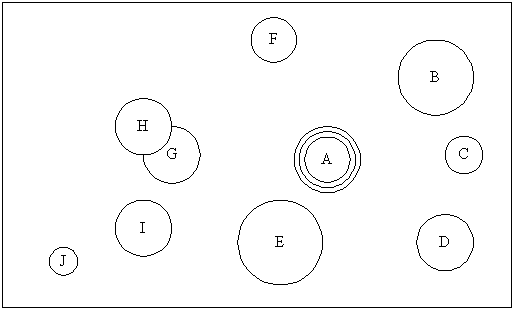
Probability is not the only means of addressing uncertainty. Consider the following representation of 'problem space':
The axes of this picture are whatever variables define the problem, e.g. if it were a logistic problem - getting from Alcatraz to Bali, say - then the horizontal axis might set out the range of difficulties that might be encountered on the way, and the vertical axis might set out the range of resources that could be utilised in overcoming these difficulties. The circles A-J represent different scenarios (hypothetical combinations of events) for this problem. Each scenario is a two-dimensional object because it describes a particular challenge and response, together with the non-zero uncertainty associated with each. (Scenarios don't have to be circular or even two-dimensional for the following argument to hold.) Scenario A is drawn with two additional concentric circles, representing upper and lower bounds resulting from probability calculations.
There are a number of points to be made in relation to this picture:
We handle uncertainty by scoping the problem space. This can be done by carefully investigating the limits of individual scenarios using probabilistic tools (as with scenario A), and/or by looking at the overlaps and gaps between a number of different scenarios;
In practice, when we make decisions, we: (1) Compare the prevailing conditions with remembered experiences; (2) Select the set of remembered experiences that best fits the prevailing conditions; (3) Fine-tune the selected set of remembered experiences and our view of the prevailing conditions to improve the fit between the two; (4) Act according to this modification to what happened last time. Applied to the 'problem space' picture, this decision methodology (which has also been described here) implies that we first look at the overlaps and gaps between different scenarios, and only when we have down-selected a small number of best-fit scenarios do we investigate their limits using probabilistic tools;
Therefore it seems that probabilistic tools do have a role, but only within the context of a framework for handling an ensemble of scenarios. Attempting to make decisions on the basis of probabilistic projections alone misses the overall picture. It can be misleading and does nothing to engender confidence in the final decision. In other words, probabilistic tools cannot on their own handle the uncertainty inherent in complex decision problems;
In practice, if you have a good framework for handling an ensemble of scenarios then there is little need for probabilistic tools.
Regarding the use of scenarios: typically, these are formulated using theoretical or computational models suitable for predicting particular features of the decision problem. Different scenarios may be generated either by inputting different parameters to one model or by inputting the same parameters to different models. The latter approach is appropriate if (as is usually the case) individual models contain questionable approximations or if they are being applied outside their domain of validity. It necessitates the existence of a toolbox of models, which is a topic in itself...
The toolbox approach may be summed up by the maxim, "Use the right tool for the job". Pragmatic and empirical, it stands in stark contrast to Popper's view of the role of theory within scientific method. One of the many virtues of the toolbox approach is that it explains one of the most enduring puzzles in epistemology, viz. scientists' persistent use of a principle of simplicity, usually expressed as 'Ockham's razor': "Entities are not to be multiplied beyond necessity". Why should a scientist be suspicious of a very complicated theory? It's because theories are tools. If the application of a theory to a particular problem is very complicated then it's probably the wrong tool for the job, and there's a more appropriate theory somewhere else, if only we looked for it. Significantly, Howson and Urbach can find no explanation for simplicity within their Bayesian framework.
It is concluded that any design of an automated learning engine must be able to manipulate an ensemble of scenarios generated using a toolbox of models.
Alan Bullock and Oliver Stallybrass (eds.), The Fontana Dictionary of Modern Thought (Fontana 1977).
Colin Howson and Peter Urbach, Scientific Reasoning - The Bayesian Approach (Open Court 1989).
Click here to go back
Copyright © Roger Kingdon 2004